Apache Hudi 在机器学习数据处理与存储支持服务中的应用
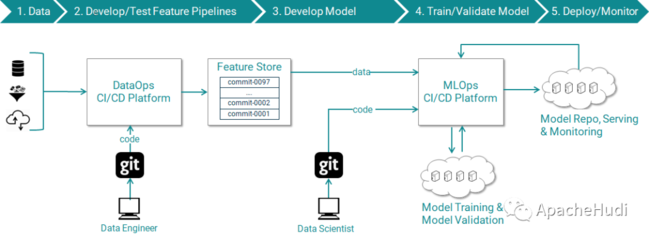
Apache Hudi 是一个开源的数据管理框架,专为高效的数据湖操作而设计,它通过提供事务支持、增量数据摄取和实时查询等功能,为机器学习的数据处理与存储支持服务提供了强大支持。将 Apache Hudi 应用于机器学习领域,可以帮助团队高效管理大规模数据,加速模型训练和部署。以下是详细的应用步骤和优势分析。
一、Apache Hudi 概述及其对机器学习的意义
Apache Hudi(Hadoop Upserts Deletes and Incrementals)是一种用于大数据湖的数据管理工具,它支持数据的插入、更新和删除操作,同时提供增量数据处理能力。在机器学习中,数据往往规模庞大、变化频繁,需要实时或近实时地处理新数据、修正历史数据。Hudi 的事务性保证和增量处理功能,使得机器学习管道能够更加可靠地处理数据更新,减少数据不一致的风险,从而提高模型的准确性和可靠性。
二、应用 Apache Hudi 到机器学习数据处理的关键步骤
- 数据摄取与集成:使用 Hudi 的增量摄取功能,将来自多种源(如 Kafka、数据库或日志文件)的数据高效加载到数据湖中。通过 Hudi 的表类型(如 Copy-on-Write 或 Merge-on-Read),可以优化写入性能,确保机器学习管道能够快速处理新数据。例如,在实时推荐系统中,Hudi 可以捕获用户行为数据流,并立即更新到数据湖中,供模型训练使用。
- 数据版本管理与事务支持:Hudi 提供 ACID 事务保障,这在机器学习中至关重要,尤其是当多个团队同时访问和修改数据时。通过 Hudi 的时间旅行查询,可以回溯历史数据快照,方便模型调试和实验复现。例如,如果模型在某个版本的数据上表现不佳,团队可以轻松恢复到之前的干净数据状态。
- 增量数据处理与流式机器学习:Hudi 支持增量拉取(incremental pull)功能,允许机器学习管道仅处理自上次运行以来的新数据或变更数据。这大幅减少了计算资源消耗,并支持近实时的模型更新。例如,在欺诈检测场景中,Hudi 可以仅处理最新的交易数据,快速训练和部署模型,提高响应速度。
- 数据存储优化与查询加速:Hudi 通过索引和压缩机制优化数据存储,减少了查询延迟。对于机器学习工作负载,这意味著更快的特征提取和数据探索。用户可以结合 Apache Spark 或 Flink 等计算引擎,直接查询 Hudi 表,获取用于训练的特征数据,从而加速模型迭代。
- 集成现有机器学习生态系统:Apache Hudi 可以与常见的机器学习工具(如 TensorFlow、PyTorch 或 MLflow)无缝集成。通过数据湖的统一存储,团队可以共享特征库,避免数据冗余,并支持端到端的机器学习生命周期管理。例如,使用 Hudi 存储特征数据,并通过 MLflow 跟踪实验,实现高效的模型治理。
三、优势与挑战
应用 Apache Hudi 到机器学习数据处理和存储支持服务中,带来多项优势:
- 提高数据可靠性和一致性:事务支持确保数据更新不会破坏管道。
- 降低运维成本:增量处理减少全量数据扫描,节省计算资源。
- 加速模型迭代:快速数据访问和版本控制促进实验和部署。
也需注意挑战,如初始配置复杂性、对团队技能的要求(需熟悉大数据生态系统),以及可能的数据延迟问题。建议从小规模试点开始,逐步扩展到生产环境。
四、实际案例与最佳实践
以一家电商公司为例,他们使用 Apache Hudi 管理用户行为数据湖。通过 Hudi 的增量摄取,他们每天处理数百万条新数据,支持实时推荐模型的训练。同时,利用 Hudi 的时间旅行功能,团队可以对比不同时间段的数据表现,优化模型策略。最佳实践包括:定期监控 Hudi 表性能、使用合适的表类型(例如,Merge-on-Read 用于高写入频率场景),以及与数据治理工具(如 Apache Atlas)集成,确保数据合规性。
Apache Hudi 作为数据湖管理工具,为机器学习的数据处理与存储提供了高效、可靠的解决方案。通过合理应用,团队可以构建可扩展的机器学习管道,提升整体业务价值。建议结合实际需求,参考官方文档和社区资源,逐步实施和优化。
如若转载,请注明出处:http://www.zdchumei.com/product/20.html
更新时间:2026-04-16 18:01:52









